The goal was to build a high-quality, balanced dataset to create a multi-label classification model that could classify SEC explanatory notes with multiple relevant labels.

“Annolive has been great for our team. The highlight feature and ability to load rule-based pre-labeled data saved us hours of work, while the class balance view made tracking our annotated data effortless and more insightful.”
Assistant Professor, Washington University
Challenges
- Volume of Data: A high volume of data required scalable and efficient annotation. There were a total of 50k+ SEC notes
- Multi-Label Complexity: Each document could have several labels, making consistency a challenge.
- Quality Assurance: It was important to ensure the labels were accurate while keeping up with the pace.
- Balanced Class Representation: The dataset needed a good mix of all classes to create a reliable model.
Solution Approach
Here’s how MJ used Annolive to address each challenge, step by step:
1. Define the Labels and Guidelines
First, MJ identified the labels needed for the SEC notes and made sure everyone understood the guidelines for labeling. This helped create a consistent foundation for the annotations.
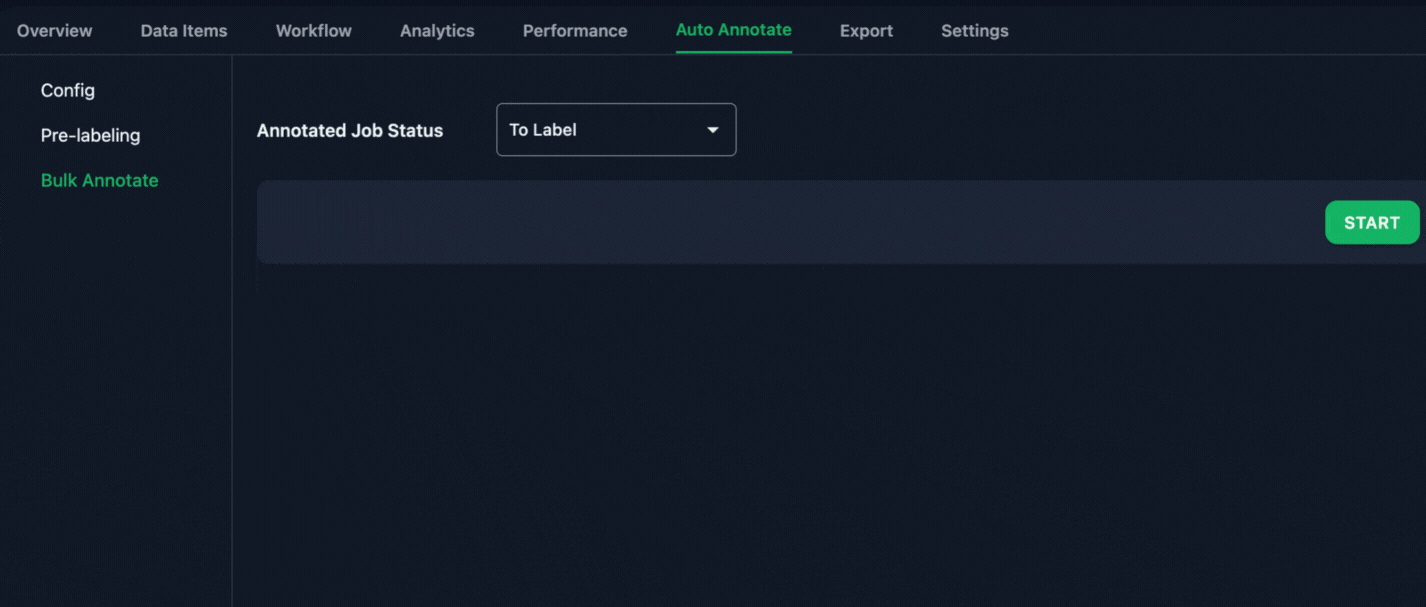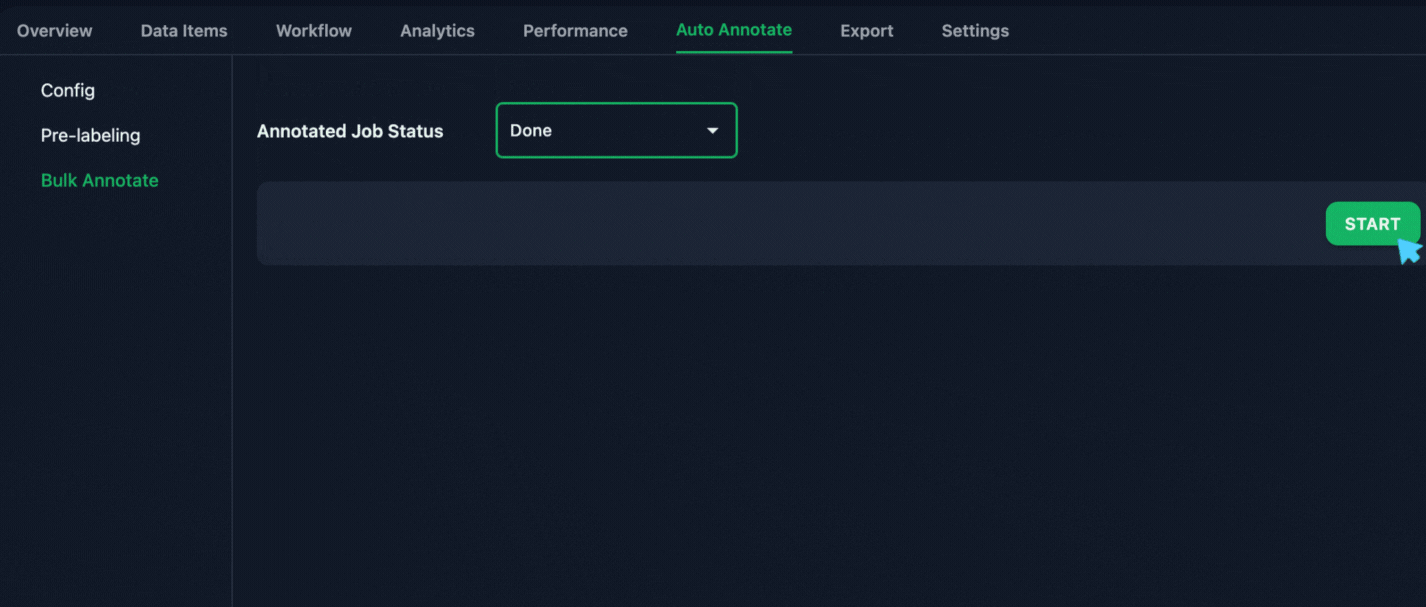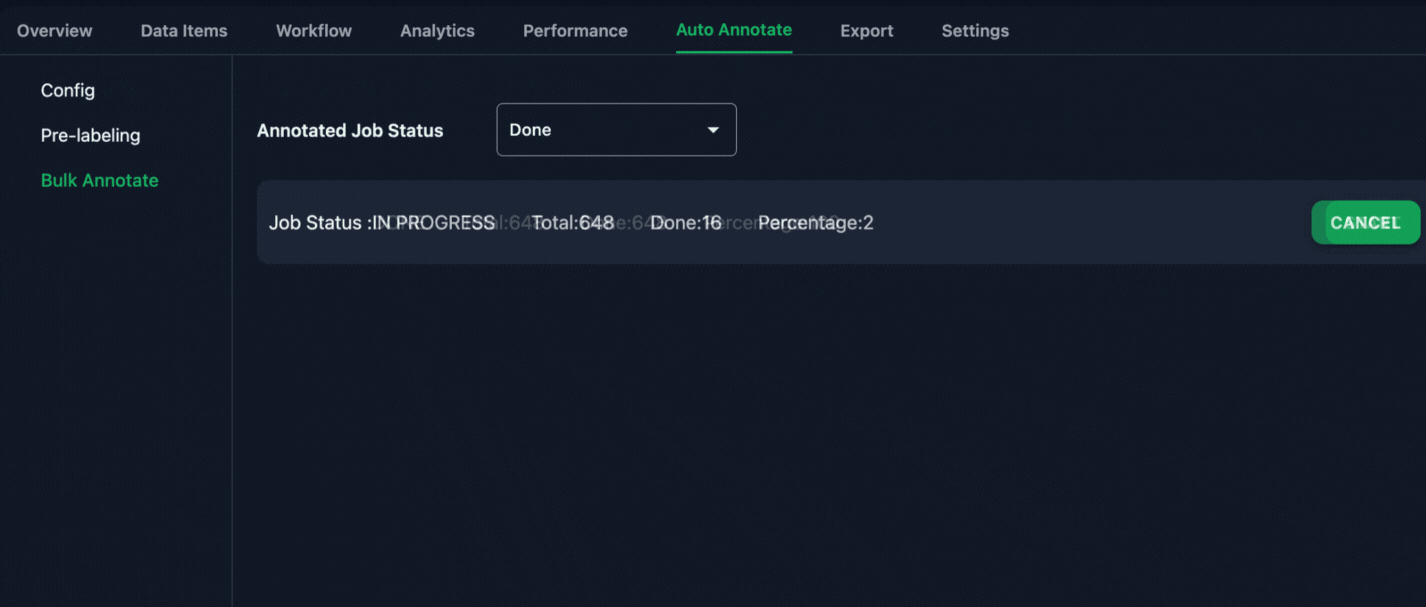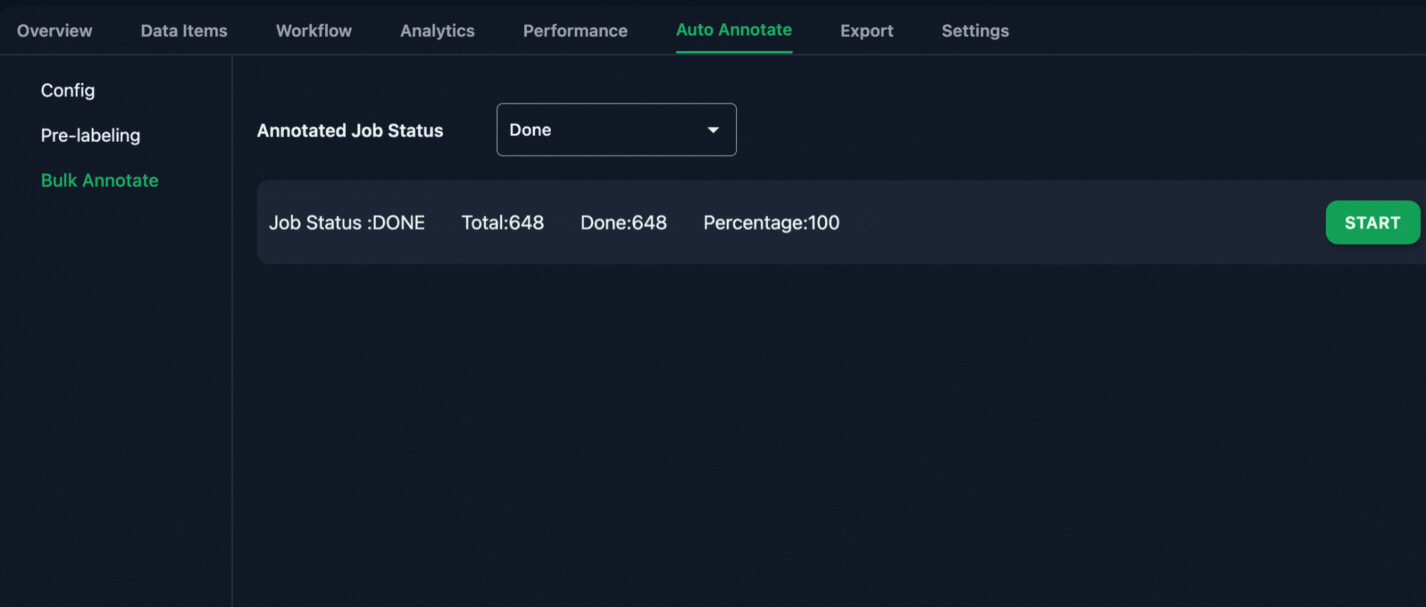
2. Initiate Annotation Using AI/Rule based Bulk Annotation
To speed up the process, MJ used Annolive’s AI bulk annotation tool to make a “first pass” of labels on the data. This tool automatically labeled the data, giving MJ a solid starting point for further refinement.
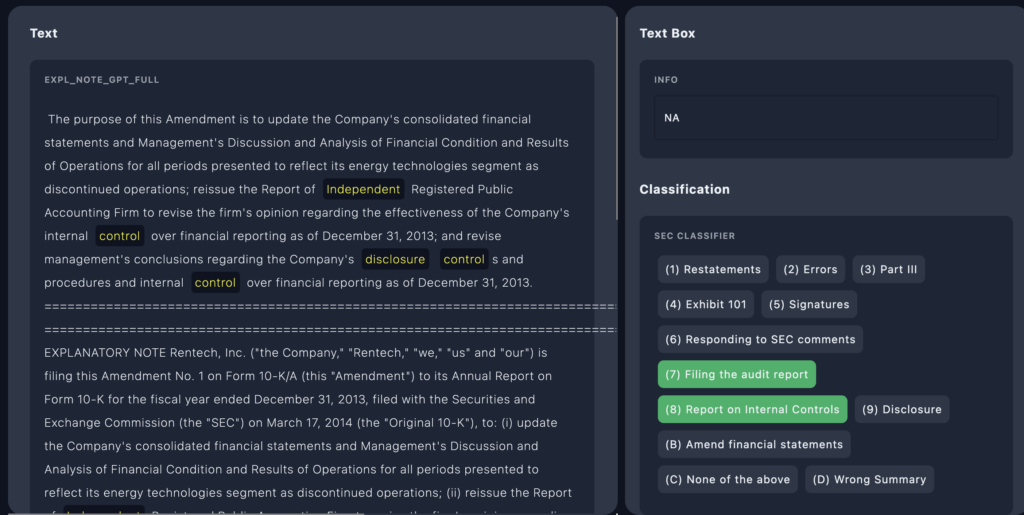
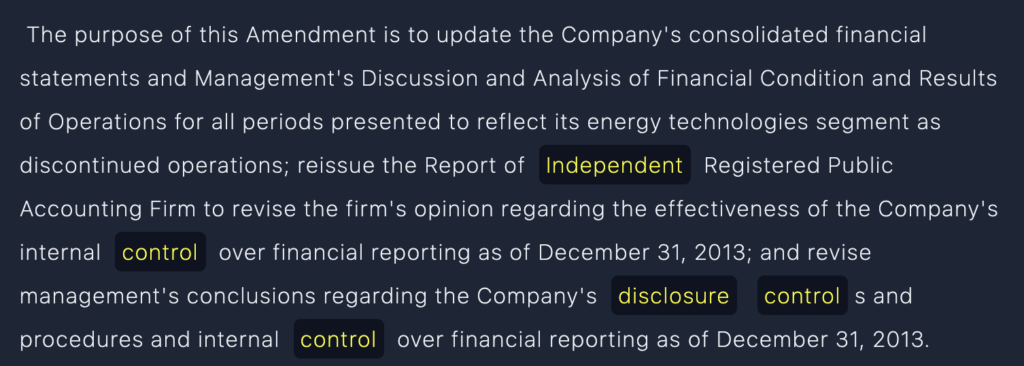
3. Highlight Key Words Using the Highlight Feature
To make labeling easier, MJ used Annolive’s highlight tool, which allowed annotators to mark key words in each document. This helped them focus on important parts, improving the speed and accuracy of the labels.
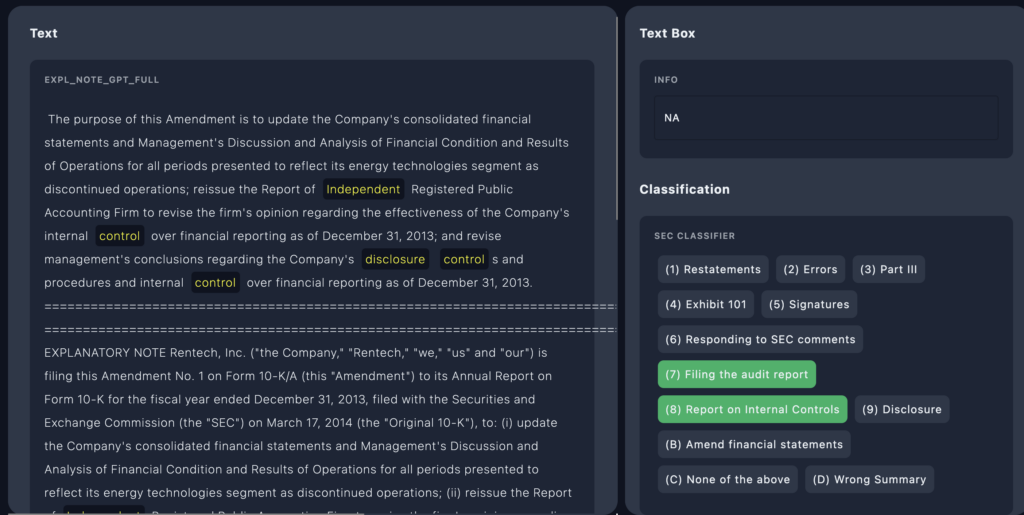
4. Refine AI/Rule based Annotations Manually
After the AI pass, MJ and her team checked the automated labels, making adjustments where necessary. This step ensured that each label was accurate, especially for complex or nuanced cases
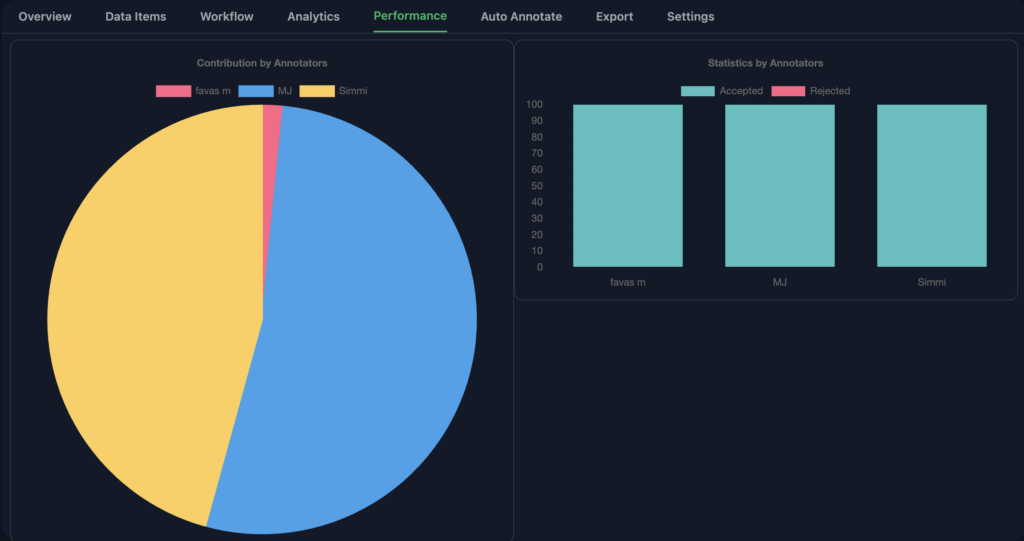
5. Track Annotator Performance with Real-Time Metrics
To improve efficiency, MJ monitored annotator performance in real-time. She could see metrics like annotations per hour and error rates, allowing her to make adjustments as needed to keep the workflow smooth.
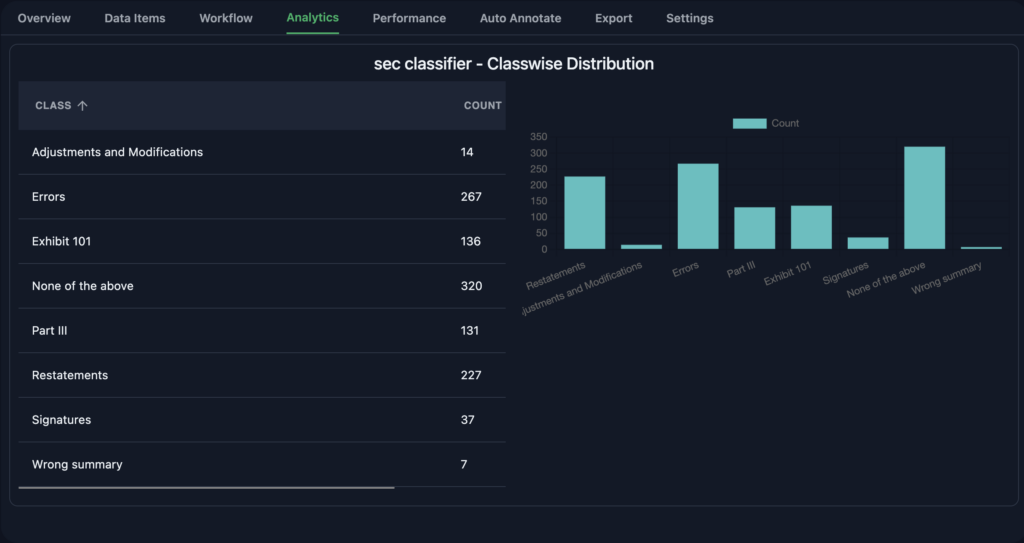
6. Analyze Class Distribution Using Data Analytics
MJ used Annolive’s data analytics to track how many labels each class had. By keeping an eye on class distribution, she ensured there was a balanced dataset, which is important for training a strong model.
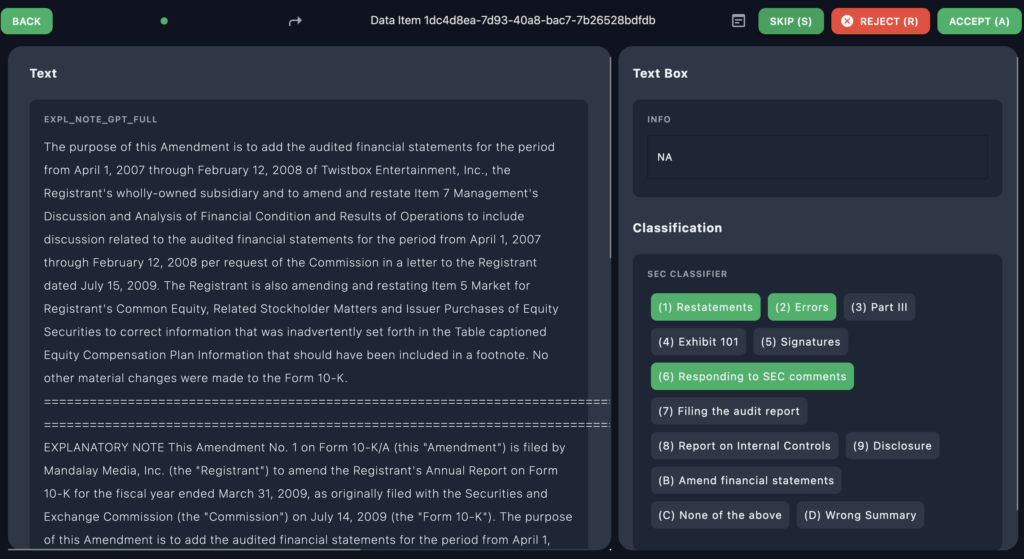
7. Conduct Quality Control on Final Annotations
To make sure the data was high quality, MJ did a final quality check by reviewing a sample of the annotated data. She checked the accuracy and gave feedback to the annotators as needed, ensuring the labels were correct and consistent.
Outcome
- Time Savings: AI bulk annotation helped MJ handle the large dataset quickly.
- High-Quality Labels: Manual checks and quality controls ensured accuracy.
- Balanced Dataset: Monitoring class distribution helped MJ keep the dataset well-rounded.
FAQs
Frequently asked questions
What is a balanced dataset in machine learning?
Why is class balancing important for multi-label classification?
What strategies can be used to handle imbalanced datasets?
What tools can help with building balanced datasets?
How do you track class distribution during dataset creation?
What are the common challenges in building datasets for multi-label models?
How does AI-assisted annotation improve dataset creation?
How can annotation quality be ensured in large datasets?
Can you use rule-based systems for initial labeling?
What are the outcomes of using balanced datasets in machine learning models?
Question not answered above?
Last Updated on 19/11/2024